
「生成AI 検索 (Google の AI Overview / AI Mode) で見つけてもらうために llms.txt を置くべき」「コンテンツは Chunking (細切れ化) しないと AI に拾われない」 — こうした GEO (Generative Engine Optimization = 生成AI 検索向けの最適化) の常識を、Google が2026年に公式に否定しました[1]。
私も RevenueScope を作る過程で、GEO 業界の手法を解説する記事を多数読んできましたが、「結局どれが本当に効くのか」 を判断する一次情報がなく、Google 公式の声明を待っていました。今回 Google Search Central が公開したガイドは、長年議論されていた「やるべきこと」 と「やらなくていいこと」 を、検索プラットフォーム側の運用者が初めて公式に切り分けた重要な一次情報です。
本記事では Google 公式ガイドで発表された 「やらなくていい5つの GEO myth」 を verdict 完全形と一緒に整理し、「じゃあ何をするべきか」 という GEO の本線・さらに2026年以降に注視すべき新しい軸 (agentic experiences = AI エージェント向け体験) まで一気に通します。
まとめ解説動画
目次
この記事のまとめ#
-
Google 公式が GEO myth を5件否定
llms.txt 不要 / Chunking 不要 / AI 専用書き換え不要 / Inauthentic mentions (= 不自然な言及狙い) 無効 / 構造化データ過信不要 — 業界で「やるべき」 と言われていた手法が公式に「不要」 と明言された[1]
-
GEO の本線 = SEO ベスプラ継続 + non-commodity content
AI Overview や AI Mode は Google の検索ランキングの上に RAG (Retrieval-augmented generation = 検索拡張生成) と Query fan-out (= 1つの質問を関連クエリに展開して情報収集) で乗っているため、SEO で100点を取りに行く動きと GEO 対策は本質的に同じ[1][2]
-
新規軸 = agentic experiences (AI エージェント向け体験)
browser agent や Universal Commerce Protocol (UCP) など、AI が自律的に website を操作する時代の準備が公式言及範囲に入った。MCP (Model Context Protocol) の流れと連動する次の戦場[1][3]

1.Google公式がGEOmythを5件否定:何を信じないか#
Google Search Central が公開した「Optimizing your website for generative AI features on Google Search」 ガイド (2026年版) では、生成AI 検索向けの最適化として やる必要がないこと が5件明示されました[1]。順番に Google verdict (= 公式判定) を完全形で引用し、業界でこの myth が広まった背景と一緒に整理します。
1.1myth1:llms.txtやAI向け専用ファイルは不要#
"LLMS.txt files and other 'special' markup: You don't need to create new machine readable files, AI text files, markup, or Markdown to appear in generative AI search. Note that Google may discover, crawl, and index many kinds of files in addition to HTML on a website: this doesn't mean that the file is treated in a special way."[1]
(意訳:生成AI 検索に出るために、新しい機械可読ファイル・AI テキストファイル・マークアップ・Markdown を作る必要はない。Google は HTML 以外のファイルも発見・クロール・インデックスし得るが、それは特別扱いされることを意味しない)
業界では「llms.txt を root に置くと AI クローラーが優先的に読む」 という説が広まりましたが、Google 系 (AI Overview / AI Mode) では効果がないと公式に明言されました。Anthropic / OpenAI / Perplexity 等の他 AI 向けの llms.txt は別議論として残しても OK ですが、Google 向けは作る必要なしです。
1.2myth2:コンテンツのChunking(細切れ化)は不要#
"'Chunking' content: There's no requirement to break your content into tiny pieces for AI to better understand it. Google systems are able to understand the nuance of multiple topics on a page and show the relevant piece to users. However, sometimes shorter (or longer!) pages can work well depending on your audience and subject matter."[1]
(意訳:AI が理解しやすいように、コンテンツを細かいピースに分ける必要はない。Google のシステムは1ページ内の複数トピックを理解して該当部分を読者に提示できる。ただし、対象読者やテーマによっては短い page・長い page どちらも有効になり得る)
「LLM は長文を理解できないから、AI 検索向けに段落を短く・1トピック1ページに分けるべき」 という主張も業界で広まっていますが、Google は「1ページに複数トピックがあっても適切に切り出せる」 と明言。記事の長さは読者にとって最適な長さで決めればよい、ということです。
1.3myth3:AI専用の書き換えは不要#
"Rewriting content just for AI systems: You don't need to write in a specific way just for generative AI search. AI systems can understand synonyms and general meanings of what someone is seeking, in order to connect them with content that might not use the same precise words. This means you don't have to worry that you don't have enough 'long-tail' keywords or haven't captured every variation of how someone might seek content like yours."[1]
(意訳:生成AI 検索のためだけに特定の書き方をする必要はない。AI システムは同義語や一般的な意味を理解できるため、検索者と全く同じ単語を含まないコンテンツでも結びつけられる。long-tail キーワードや表現の variation を全網羅していなくても気にする必要はない)
「AI に拾われる文体」「LLM フレンドリーな表現」 を別に書く必要はなく、人間向けに書けば AI も理解する、というシンプルな整理です。同じ意図を別の言葉で書いても意味は伝わるので、long-tail キーワードを過剰に詰め込む必要もありません。
1.4myth4:Inauthenticmentions(不自然な言及)は無効#
"Seeking inauthentic 'mentions': ...seeking inauthentic 'mentions' across the web isn't as helpful as it might seem. Our core ranking systems focus on high-quality content while other systems block spam; our generative AI features depend on both."[1]
(意訳:不自然な言及を web 上で集めることは、思うほど役に立たない。Google の core ranking system は high-quality content を評価する一方で別の system が spam をブロックしており、生成AI 機能はその両方に依存する)
「AI に取り上げられるためには自社サービス名が web 上で大量に言及されている必要がある」 → 「言及数を稼ぐためにブログや forum で組織的に mention を仕込む」 という流れがありますが、Google の core ranking system は high-quality content を評価する一方で spam ブロックも働くため、組織的な mention 工作は逆効果になり得ます。コミュニティやフォーラムでの自然な engagement を通じた mention は別軸で価値があります。
1.5myth5:構造化データ(schema.org)への過信は不要#
"Overfocusing on structured data: Structured data isn't required for generative AI search, and there's no special schema.org markup you need to add. However, it's a good idea to continue using it as part of your overall SEO strategy, as it helps with being eligible for rich results on Google Search."[1]
(意訳:生成AI 検索のために構造化データは必須ではなく、特別な schema.org マークアップを追加する必要もない。ただし、Google 検索の rich result eligibility のために、通常 SEO 戦略の一部として継続使用するのは良い)
ここは誤解されやすい部分です。「schema.org 全廃」 ではありません。rich result (= リッチリザルト = 検索結果に画像や評価が表示される拡張表示) を狙う通常 SEO 目的での schema.org 利用は 引き続き推奨。Google が「不要」 と言っているのは「GEO のためだけに special markup を盛る」 行為で、Product / Article / FAQ 等の標準 schema.org は維持で OK です。
2.じゃあ何をするべきか:GEOの本線#
GEO の本線は驚くほどシンプルです。SEO ベスプラ (= best practice = 推奨手法) を継続することが GEO 対策そのもの だと Google は明言しています[1]。

理由は AI Overview や AI Mode の仕組みにあります。Google は生成AI 機能の根幹に RAG (Retrieval-augmented generation = 検索拡張生成・情報を grounding して回答精度を上げる手法) と Query fan-out (= ユーザーの1つの質問から関連クエリを並列展開して情報収集する手法) を採用しています[1][2]。AI 機能は Google の検索インデックスから関連 page を取得して回答を生成するため、「Google 検索で上位に来る」 = 「AI Overview に引用される」 という対応関係になります。別に「GEO ランキング system」 があってそれを別個に gameする、という構造ではありません。
その上で、Google が「これをやるべき」 と明示する3つの軸は次の通りです。
2.1non-commoditycontentを書く#
「7 Tips for First-Time Homebuyers」 のような誰でも書ける commodity (= 平凡な) コンテンツではなく、「Why We Waived the Inspection & Saved Money」 のような 1次経験・専門角度の non-commodity コンテンツが推奨されます[1]。AI が引用する価値のあるユニークな視点が含まれているかが評価軸です。
実務的には「自分の prod / project / org でしか書けない data や経験」 を冒頭に置く、「他の記事と差別化できる仮説や反証」 を1つ以上含める、といった指針になります。汎用の how-to は AI が直接回答できるため、AI Overview に引用されるよりも自社サイト訪問の incentive が薄れていきます。
2.2technicalclarityを保つ#
page が indexable (= インデックスされる状態) + crawlable (= クローラーが回れる状態) + snippet eligible (= 検索結果スニペットに出る要件を満たす) であること・page experience (表示速度・モバイル対応・main content の見やすさ) を整えることが基礎条件です[1]。
これは GEO 専用の新規対応ではなく、従来 SEO で「技術 SEO」 と呼ばれていた領域そのものです。生成AI 機能も検索インデックスを base にしているため、index に入っていない page は AI Overview の引用候補にもなりません。
2.3variation量産は避ける#
「ユーザーが検索しそうな表現の全 variation 用に別 page を作る」 のは Google の scaled content abuse spam policy (= 大量生成コンテンツ濫用ポリシー) 違反に該当します[1]。AI で記事を量産して keyword variation を埋めにいく動きは、core ranking system + spam filter の両方で減点対象になります。
RevenueScope でも「空白を作らない」 原則として価格・FAQ・ブランドの structural completeness (= 構造的な完備性) は埋めますが、これは variation 量産とは別軸です。「同じ内容を表現だけ変えて N page」 ではなく「読者が必要とする情報軸を網羅して1 page で完備」 が正しい方向性です。
3.新規軸:AIエージェント向け体験を2026年以降は注視#
Google ガイドの末尾で言及されている新しい軸が agentic experiences (= AI エージェント向け体験) です[1][3]。これは AI が自律的に website にアクセスして予約・購入・情報収集を行う時代の準備で、2026年以降の GEO の次の戦場になります。

3.1Browseragentsがwebsiteを直接navigateする#
Google 公式は「Browser agents may access your website to gather the data they need to complete these tasks, such as analyzing visual renderings (like screenshots), inspecting the DOM structure, and interpreting the accessibility tree.」[1] と書いており、AI エージェントが screenshot / DOM / accessibility tree (= 支援技術向けの構造化情報) の3つを通して website を解釈 する時代を見据えています。
agent-friendly site の best practice は web.dev で公開されており[3]、semantic HTML (<button>, <a>)・ARIA 属性・stable layout・click target ≥8px などが推奨されています。これは accessibility の延長線上で、人間と AI 双方にとって読みやすい page 構造を作ることがそのまま GEO 投資になります。
3.2UniversalCommerceProtocol(UCP)とMCPecosystem#
Universal Commerce Protocol (UCP) など、検索エージェントが商品比較や注文を実行できる protocol (= 通信規約) が emerging (= 出現中) で[1]、既存の MCP (Model Context Protocol = AI モデルが外部データソースに接続するための標準規格) の流れと地続きで「AI が自分の代わりに買い物する」 体験が現実化しつつあります。
MCP は Anthropic が2024年11月に公開した規格で、ChatGPT / Cursor / Claude Desktop / Cline / Continue などの AI agent が外部 data source に標準化された方法で接続できる仕組みです。RevenueScope も自社の MCP server を公開しており、AI から RevenueScope のデータ (業界別 RPS ベンチマーク等) を直接問い合わせられる経路を提供しています。
3.3RevenueScopeのdogfooding接続#
RevenueScope は agentic experiences を他人事ではなく 当事者軸 として作っています。Google 公式が「extra time があれば agent-friendly site の best practice (web.dev/articles/ai-agent-site-ux) も check してほしい」 と書いている範囲は、まだ早い段階の準備フェーズですが、「次に何が来るか」 を1段先に意識しておく ことが、3ヶ月後・半年後の差を作ります。
GEO myth を整理して「やらなくていいこと」 をやめた後の時間は、agentic experience 軸 (semantic HTML + accessibility 整備 + MCP / UCP の動向 watch) に振るのが投資対効果として最も筋がよさそう、というのが現時点の整理です。
神話を一つずつ整理して「やらなくていいこと」を手放した後、最後に残るのは別の問いです。自社の現在地——AI 検索に出ているのか、AI 経由の流入は増えたのか、それで売れているのか——を、いま測れていますか。 「やらなくていい5つ」を捨てるのは前半戦で、後半戦はこの3つの問いに数字で答えられるかどうかです。この記事のクラスタとして、それぞれを掘り下げた3本も用意しています。
RevenueScopeの解決策
「GEO は神話だ」 「AI 経由の流入なんて測れない」。そう言われがちですが、現在地の3つの問い——出ているか/増えたか/売れたか——は、それぞれ測れます。問題は、GA4 も Search Console も AI ソース別の流入をこの3層に分解してくれないことです。RevenueScope はこの3層をそのまま見せます。
① 露出量(出ているか)。 どのページが、どの AI アシスタントの回答に、どれだけ引用されているか。AI 検索での見え方そのものは GA4/GSC の指標には現れません。露出量をどう測るかはAI検索で自社がどれだけ出ているかで詳しく扱っています。
② AI 流入の本物の増分(増えたか)。 AI 経由のセッションが増えても、それが本当に増分なのか、もともと来ていた人の経路が変わっただけなのかは、流入数だけでは見分けられません。RevenueScope はソース別に分けて、本物の増分を売上で裏取りします。見分け方はAI流入が増えた=効果ではないに整理しました。
③ ソース別の売上(売れたか)。 RevenueScope は、ChatGPT・Claude・Perplexity・Gemini・Copilot の回答内リンクから来た流入を、着地ページ × AI ソース別に集計し、その売上まで見せます。GA4/GSC では作れないビューです。AI 引用が実際にどれだけ売上を生んでいるかを、推測でなく数字で確かめられます。なお AI のおすすめは大手に偏りがちですが、中小でも崩し方はあります(AIのおすすめが大手に偏る理由)。
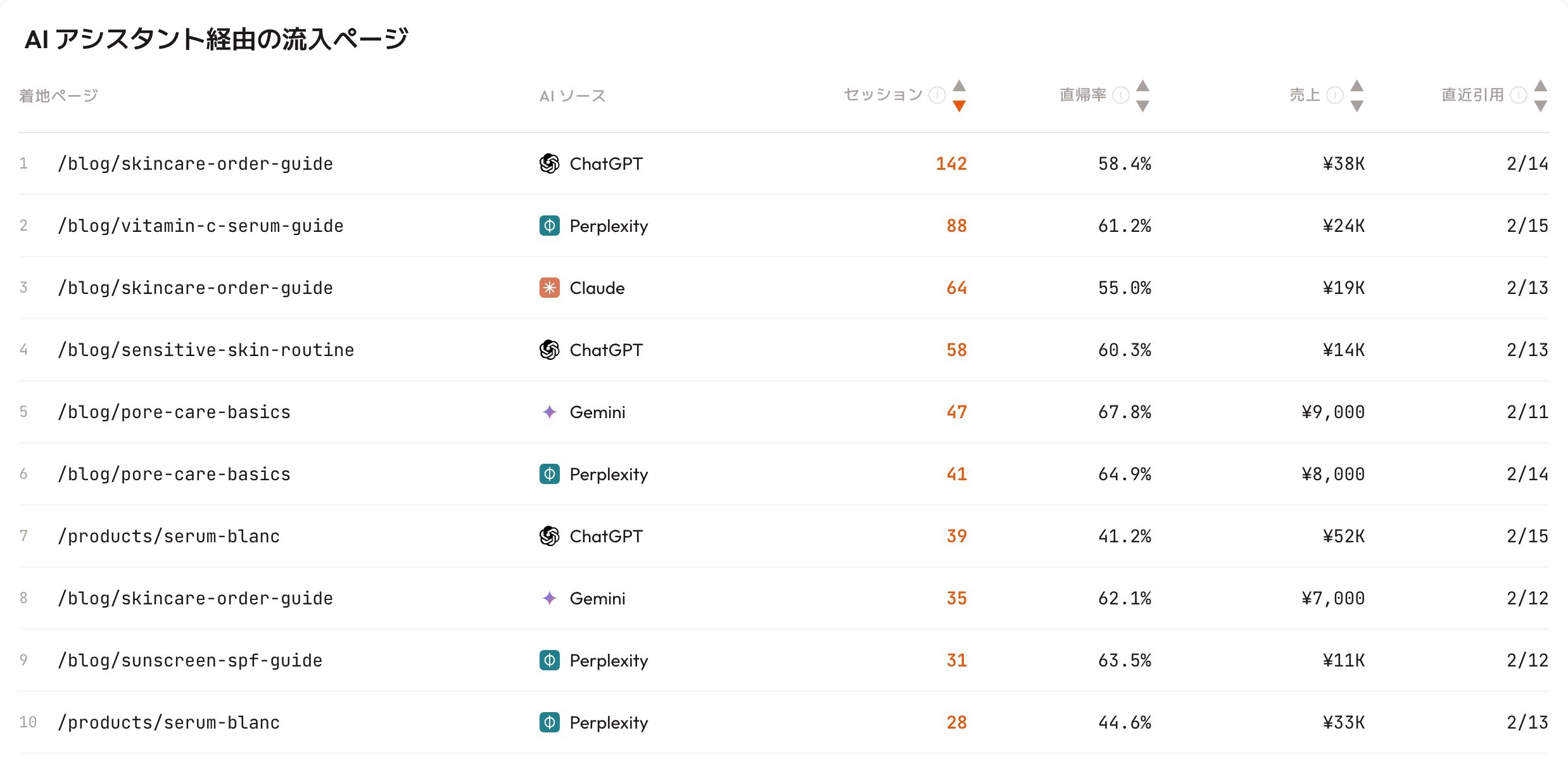
RevenueScope のAI流入ビュー(表示はデモデータ)。どのページがどのAIに引用され、どれだけ売上を生んだかを1画面で見比べる。
たとえば上の画面では、/blog/skincare-order-guide に ChatGPT 経由で 142 セッション・売上 ¥38K。Perplexity や Claude からの流入も、ページ別・ソース別に一覧で見比べられます。どの記事が、どの AI に引用され、どれだけ売上につながったか。「測れない」 と思われていた領域が、ここでは具体的な数字になります。GEO を神話で終わらせず、AI 引用流入を売上で評価する。これが、AI 検索時代に流入を取りこぼさないための次の一手です。
4.よくある質問#
Q1.既にllms.txtを公開しています。削除すべきですか?#
Google 系 (AI Overview / AI Mode) では効果がないので削除して OK です。Anthropic / OpenAI / Perplexity 等の他 AI 向けは crawler 仕様が異なるので別議論で残置しても問題ありません。判断軸は「保守コストと、Google 以外の AI からの流入期待値の比較」 になります。
Q2.Chunkingでpageを1トピック1ページに分割していました。統合すべきですか?#
Google は multi-topic page から関連 section を切り出して LLM に渡すので、分割した page を統合しても OK です[1]。ただし topic 関連性が薄い page を無理に統合すると page experience が下がる可能性があるため、読者目線で「読みやすい単位」 で判断してください。
Q3.schema.orgをGEO用に盛っていました。撤去すべきですか?#
rich result 用の通常 schema.org (Product / Article / FAQ 等) は 維持で OK・むしろ rich result eligibility のため推奨継続です[1]。「GEO のためだけに special markup を盛った」 部分 (例:AI 用カスタム schema や、AI に強調されるためだけに追加した冗長 markup) は整理してかまいません。
Q4.AI専用に書き直した文体・KW詰込みは元に戻すべきですか?#
「AI 専用文体」 を別 page で用意していたなら統合して OK・人間向けに自然な文体に戻してください。long-tail KW スタッフィング (= 不自然な詰込み) は元々非推奨でしたが、特に AI 用に過剰詰込みしていた箇所は整理推奨です。Google は「synonyms と一般的な意味を理解できる」 と明言しています[1]。
Q5.もし組織的に外部blog/forumで自社名をmention増やしを発注していたら、続けるべきですか?#
即停止推奨です。Google spam system の filter 対象になり、自然 engagement (コミュニティ議論への参加・technical blog 引用) と区別されます[1]。authentic な engagement 軸 (例:自社 product に関連する technical 議論への参加・source 解説への deep comment) に切り替える方が、長期的にも spam リスクを抱えず GEO 評価にもポジティブに働きます。
どの広告が売上を生んでいるか、一目でわかる
月5,000セッションまで、AIアナリストもずっと無料。クレジットカード不要。最短5分で導入。
参考文献#
- Google Search Central 「Optimizing your website for generative AI features on Google Search」 2026年
- Google Search Central Blog 「How Search ranking systems work」 2023年 (RAG / Query fan-out 関連の background)
- web.dev 「Build agent-friendly websites」 2025-2026年




