ChatGPTやPerplexityに、自社が引用されているか。この1年、それを気にする担当者は一気に増えました。専用ツールを入れて、何回言及されたかを毎週ながめている人もいます。けれど、次に手を入れるべき記事は、引用された数を数えるだけでは見つかりません。
見落とされがちなのは、人はちゃんと来て、よく読まれているのに、AI経由ではほとんど流入していない記事です。検索やSNSからの読者は多く、滞在もそれなりにあるのに、ChatGPTやPerplexityから来た流入はほぼゼロ。この「閲覧はあるのにAI流入が乏しい記事」が、次に直す候補になります。本記事では、なぜ引用された数ではなくAI流入という別の角度で見るのか、閲覧ありでAI流入が乏しい記事をどう探すのか、手作業で探すことの限界、そして見つけたら記事の何を直すのかを、順番に整理していきます。
なお、同じ取りこぼしでも、商品ページや売れ筋の単位で探す話はAIに引用されない売れ筋|来た引用の逆側を見つけるで扱っています。本記事はそれの記事(コンテンツ)版で、用語解説や比較ガイドといった記事ページを単位に見ていきます。
まとめ解説動画
目次
この記事のまとめ#
- 「引用されない記事」を、引用された数で数えるのではなく、AI経由の流入が乏しいかどうかで見つける、という考え方です
- 人はちゃんと来てよく読まれているのに、AI経由の流入がほぼゼロの記事が、次に直す候補になります
- ただし、AI経由の流入は来た側しか見えません。引用そのものを直接数えているわけではなく、流入が乏しい記事を取りこぼしの候補として浮かび上がらせる、という見方です
- 候補が分かったら、要点を先に書く・構造を整える・一次データを足す、といった順で直していけます。手作業では候補をそろえて並べ替えるのが重く、ここを測れる状態にしておくことが効いてきます
1. 「引用されない記事」とは#
結論から言うと、ここでいう「引用されない記事」とは、AIの回答に名前が出たかどうかを直接数えるのではなく、AI経由の流入が乏しい記事のことを指します。
少し用語を整理させてください。ChatGPTやPerplexityが答えの中であるページを引いてくることを「引用」と呼びます。引用されているかをそのまま数えようとすると、各エンジンで自社のジャンルの質問を何度も打ち込み、答えに出たか出ないかを手で記録していくことになります。これは数えること自体が大変なうえ、同じ質問でも日によって違うページが返ってくるので、なかなか安定しません。
そこで本記事では、見る角度を変えます。AIの回答からクリックして実際に来た流入を「AI経由の流入」と呼び、これが乏しい記事を取りこぼしの候補として浮かび上がらせます。引用された回数そのものではなく、AI経由で来ている人の数を手がかりにする、ということです。そもそもAI検索で自社がどれだけ見えているかという露出全体の測り方は自社はAI検索にどれだけ出てる?|出る量は測れるでも扱っていますが、本記事はその中でも記事単位の取りこぼしに絞ります。GA4のような計測ツールも、流入元がChatGPTなどのAIアシスタントだと分かると、それを専用のまとまりに振り分けてくれるようになりました[1]。来た側の流入なら、こうして数として扱えます。
ここで、はっきり断っておきます。AI経由の流入は、あくまで来た側しか見えません。AIの回答に名前が出ても、クリックされずに読み流された分は、この数には入ってきません。また、AIアシスタントが流入元の情報を必ず渡してくれるわけではないので、実際にはAIから来ているのに別の流入に紛れて取りこぼされることもあります。つまり、AI経由の流入が少ない記事は「引用が完全にゼロ」と確定したわけではなく、あくまで取りこぼしの候補です。それでも、来ている人の数を手がかりにするほうが、引用回数を手で数え続けるより、ずっと現実的に次の一手につながります。なお、「引用された」ことと「AI経由で来て買われた」ことは別の層の話です。この違いはAI引用の収益貢献とは|「引用された」と「売れた」は別物でくわしく扱っているので、ここでは流入という来た側の数で見る、とだけ押さえて先へ進みます。
2. 閲覧はあるのにAI流入が乏しい記事を探す#
結論から言うと、探すコツは、AI流入がゼロに近い記事を片端から見るのではなく、人の閲覧がしっかりあるのにAI流入だけが乏しい記事に絞ることです。
AI経由の流入が少ない記事は、サイトの中にいくらでもあります。そもそも誰にも読まれていない記事なら、AIから来ていなくても不思議はありません。直す価値があるのは、検索やSNSからの読者はちゃんといて、よく読まれているのに、AI経由の流入だけがぽっかり抜けている記事です。実需はあるのに、AIの回答からは来ていない。ここに伸びしろがあります。
下の図は、ある架空のサイトで、記事ごとに人の閲覧(検索やSNSなどからの流入)とAI経由の流入を見比べたものです。
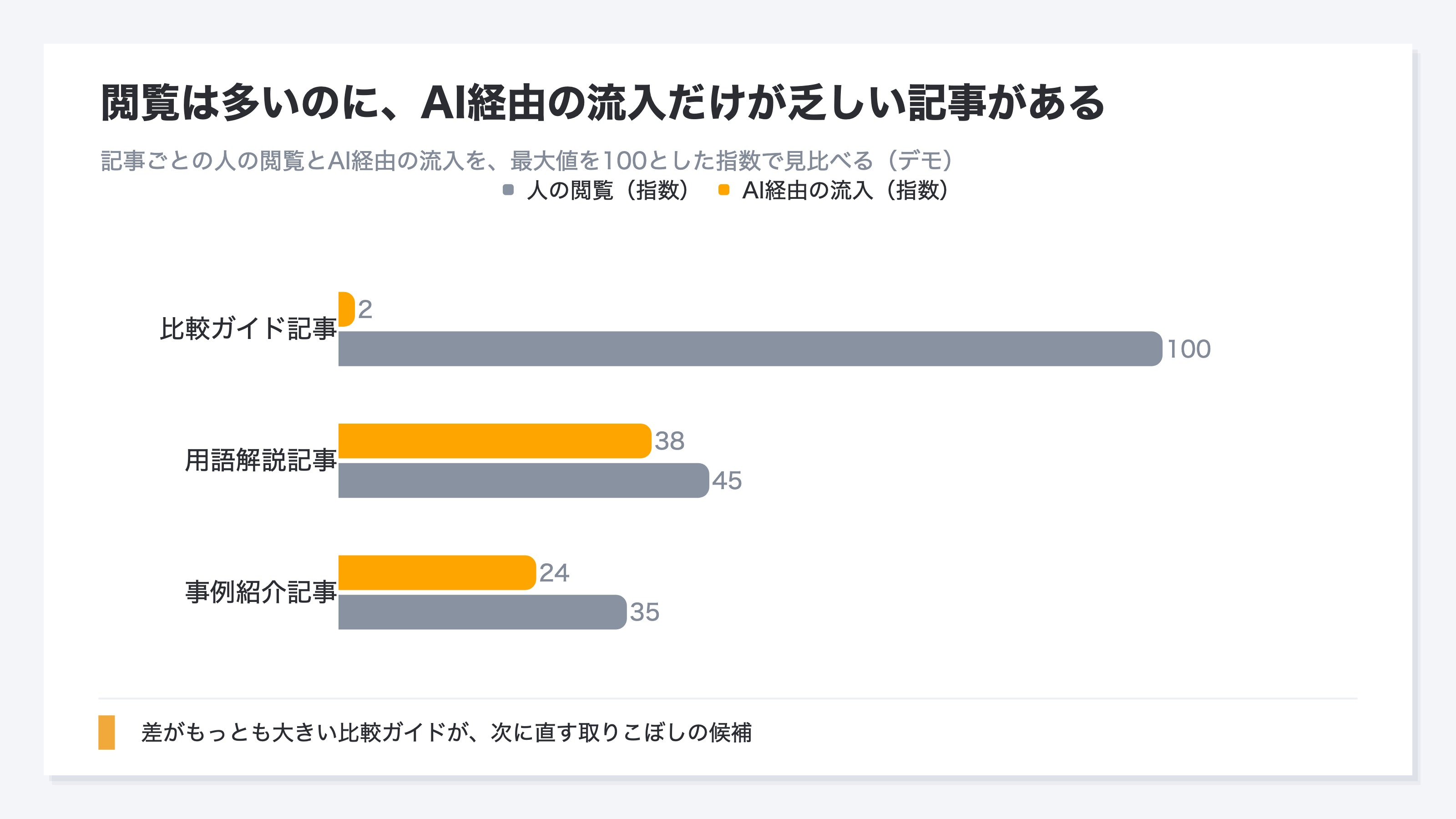
図でいちばん差が大きいのが、比較ガイドの記事です。人の閲覧は多いのに、AI経由の流入はごくわずか。よく読まれているのにAIからは来ていない、まさに取りこぼしの候補です。一方、用語解説や事例の記事は、AI経由の流入もそれなりにあり、閲覧との差は小さい。すでにAIに拾われている側なので、ここを直しても伸びしろは限られます。こうして閲覧とAI流入の差が大きい記事から見ていくと、限られた手間を効くところに向けられます。
なお、この差は二択(来た・来ない)だけでは語り切れません。どのくらいの閲覧に対してAI流入が何件か、来た人がそのページで実際に買っているか。文脈まで含めて見ようとすると、記事1本ずつを目で追うのはすぐに手に負えなくなります。
3. 手作業で探すことの限界#
結論から言うと、この「閲覧とAI流入の差」をサイト全体で見渡そうとすると、手作業では2つの壁にぶつかります。
1つ目は、AI経由の流入そのものが、手元では見えにくいことです。ChatGPTやGeminiからの流入は、設定をしていないと「どこから来たか不明」の扱いに紛れて、AI経由として切り分けられないことがあります。さらに、AIアシスタントが流入元の情報を渡してくれないこともあるので、実際にはAIから来ているのに数に入ってこない取りこぼしも起きます。GA4のAIアシスタント流入を鵜呑みにしないでも触れているとおり、素の数字はbot(機械からのアクセス)や不明な流入の紛れで歪みやすく、そのまま信じるのは危ういのです。
2つ目は、記事をまたいで並べ替えるのが重いことです。記事が数十本もあれば、1本ずつ閲覧とAI流入を書き出し、差の大きい順に並べ替え、それを毎月くり返すことになります。下の図は、この作業を手作業でやる場合と、差の大きい順に自動でそろえる場合を見比べたものです。

考え方そのものは難しくありません。閲覧とAI流入の差を見て、差の大きい記事から直す。ただ、それを記事数だけくり返し、しかも毎月続けるとなると、構造的に骨が折れます。一度なら自分の手でも確かめられますが、ページごと・月ごとに追い続けるのは、手作業には向いていない仕事です。
4. 見つけたら、記事の何を直すか#
結論から言うと、取りこぼしの候補が分かったら、要点を先に書く・構造を整える・一次データを足す、という順で直していくのが現実的です。
AIは答えを組み立てるとき、要点がはっきりしていて、根拠が示されているページを引きやすい傾向があります。だから、直す順番もそこから始めます。まず、記事の冒頭で結論や要点を先に言い切ること。次に、見出しや箇条書きで構造を整え、何がどこに書いてあるかを取り出しやすくすること。検索エンジンやAIにページの中身を伝える構造化データ[2]を添えるのも、この一環です。そして、自社ならではの実績や数字といった一次データを足し、よそにない根拠を持たせること。どれも特別な裏技ではなく、地道な手入れです。

大事なのは、直して終わりにしないことです。図のとおり、候補を抽出し、差の大きい順に並べ、記事を直したあと、AI経由の流入がどう変わったかを測る。変化を見て、効いた手は続け、次の候補に進む。この循環を回せて初めて、取りこぼしを1本ずつ拾っていけます。逆に、直したきりで変化を測らないと、効いたのかどうかが分からないまま手だけが増えていきます。
ここで気をつけたいのは、AI流入の変化を「この記事を直したからこう増えた」と断定しすぎないことです。流入は季節や他の要因でも動きますし、そもそもAI経由の流入は取りこぼしを含んだ近い値です。だから、変化は「直した記事のほうが、直していない記事より伸びやすかったか」という傾きで見て、確定した因果として扱わないのが正確です。
RevenueScopeの解決策
ここまでで、閲覧とAI流入の差で取りこぼしの候補を見つけ、直して、変化を測る、という流れは見えました。けれど、これを手作業でやろうとすると、3章の2つの壁にぶつかります。AI経由の流入を不明な流入から切り分けるのも、記事をまたいで差の大きい順に並べ替えるのも、一度なら手でできても、ページごと・月ごととなると構造的に重い。
RevenueScope は、その候補出しと継続測定を肩代わりします。クリックして来たAI流入を、bot を除いたうえでページ別に切り分け、人の閲覧(検索やSNSなどからの流入)と見比べて、閲覧はあるのにAI流入が乏しい記事——取りこぼしの候補を、差の大きい順にそろえます。さらに、来た人がそのページで買っているか(訪問あたりの売上=RPS)までつなげるので、次に直す記事を、閲覧の多さだけでなく売上への近さまで含めて選べます(表示はデモデータ)。
| 記事(ページ) | 人の閲覧 | AI経由の流入 | 訪問あたり売上(RPS) |
|---|---|---|---|
| 比較ガイド記事 | 1,240 | 3 | ¥640 |
| 用語解説記事 | 560 | 88 | ¥210 |
| 事例紹介記事 | 430 | 41 | ¥480 |
この表の読みどころは、いちばん上の比較ガイド記事です。人の閲覧は1,240と最も多く、来た人の訪問あたり売上も高いのに、AI経由の流入はわずか3件しかありません。よく読まれていて、しかも売上にも近いのに、AIの回答からはほとんど来ていない。つまり、次に直すならまずこの記事だ、と数字で名指しできます。一方、用語解説や事例の記事は、AI経由の流入もそれなりにあるので、急いで直す必要は薄い。こうして「閲覧×AI流入×売上」を1画面でそろえると、次に直す順が勘でなく決まります。
ひとつ、はっきりさせておきます。RevenueScope が数えるのは、クリックして実際にサイトに来たAI流入とその売上だけです。AIの回答に名前が出ただけ(クリックなし)の引用そのものや、「ChatGPTにどれだけ引用されているか」という回数は数えません。また、AIアシスタントが流入元を渡さない取りこぼしがあるので、AI流入の数は完全な網羅ではなく、控えめに出る近い値です。どの回答がその流入を生んだかという厳密な紐づけも追えません。RevenueScope が肩代わりするのは、クリックして来たAI流入を bot を除いてページ別に切り分け、人の閲覧や売上と見比べて取りこぼしの候補を差の大きい順にそろえるところ。どの記事をどう直すかは、あなたが決めます。
なお、AI経由の流入が「来た数」だけでなく「どのAIから来て、いくら売れたか」までどう見るかは、AIエンジン別の流入と売上|どのAIから来た客が買うかでさらにくわしく扱っています。
FAQ#
よくある質問#
Q. ChatGPTに「うちの記事は引用されてる?」と直接聞けば、取りこぼしは分かりませんか?
A. 当たりをつけるには役立ちますが、それだけでは不十分です。AIの答えは聞くたびに変わるので、1回出なくても「引用されていない」とは言い切れません。しかも記事が数十本あれば、1本ずつ手で確かめて並べ替えるのは現実的ではありません。本記事の見方は、引用そのものを数えるのではなく、AI経由の流入が乏しい記事を取りこぼしの候補として浮かび上がらせる、というものです。
Q. AI経由の流入がゼロなら、その記事は引用されていない、と断定していいですか?
A. 断定はしないほうが安全です。AIアシスタントは流入元の情報を必ず渡すわけではないので、実際にはAIから来ているのに数に入ってこない取りこぼしが起こりえます。だから、AI流入が乏しい記事は「引用がゼロ」と確定したのではなく、あくまで次に確かめて直す候補として扱うのが正確です。
Q. AIに引用されない売れ筋の記事と、何が違うんですか?
A. 単位が違います。AIに引用されない売れ筋|来た引用の逆側を見つけるは商品ページや売れ筋を単位に取りこぼしを探す話で、本記事は用語解説や比較ガイドといった記事(コンテンツ)を単位にしています。考え方は同じで、「実需はあるのにAI経由で来ていない」ものを、来た側の流入から見つける、という見方です。
まとめ#
「引用されない記事」を見つけるとき、引用された数を手で数え続けるのは、安定しないうえに記事数が増えると手に負えません。代わりに、AI経由の流入が乏しい記事を取りこぼしの候補として見るほうが、ずっと現実的に次の一手につながります。
直す価値があるのは、誰にも読まれていない記事ではなく、人はちゃんと来てよく読まれているのに、AI経由の流入だけがぽっかり抜けている記事です。閲覧とAI流入の差が大きい記事から、要点を先に書く・構造を整える・一次データを足す、という順で直していけます。
ただし、AI経由の流入は来た側しか見えず、流入元が渡されない取りこぼしも含む近い値です。だから、流入の変化は傾きで見て、確定した因果とは扱わない。そのうえで、閲覧とAI流入と売上を1画面でそろえて取りこぼしの候補を差の大きい順に並べれば、次にどの記事を直すかを、勘でなく数字で決められます。
どの広告が売上を生んでいるか、一目でわかる
月5,000セッションまで、AIアナリストもずっと無料。クレジットカード不要。最短5分で導入。