
"You need an llms.txt at the root if you want to show up in generative AI search." "Content must be chunked into tiny pieces or the AI can't understand it." A lot of the GEO (Generative Engine Optimization) "must-dos" floating around the web for the past 18 months just got officially debunked by Google in 2026[1].
I have been watching the GEO discourse closely while building RevenueScope, and the absence of a primary source has made it hard to tell which tactics actually move the needle for Google's AI Overview and AI Mode. Google Search Central's new guide is the first time the platform operator drew an explicit line between what's required and what's myth.
This piece walks through the 5 myths Google explicitly said you do not need to bother with, with the verbatim verdict for each. Then it covers what Google says actually works (foundational SEO + non-commodity content), and the new axis worth watching for 2026 onward — agentic experiences.
Table of contents
TL;DR#
-
Google officially debunked 5 GEO myths
No llms.txt / no chunking / no AI-specific rewrites / inauthentic mentions don't work / no schema overuse for GEO — Google publicly classified these as "not required" for generative AI search[1]
-
The GEO mainline = SEO best practice + non-commodity content
AI Overview and AI Mode sit on top of the Search ranking system with RAG (Retrieval-augmented generation) and query fan-out. Ranking high in regular Search ≈ being cited by AI features[1][2]
-
New axis worth watching: agentic experiences
Browser agents, Universal Commerce Protocol (UCP), and the broader MCP (Model Context Protocol) ecosystem — preparing for AI agents that navigate sites autonomously is the next investment area[1][3]
1. The 5 GEO myths Google officially debunked#
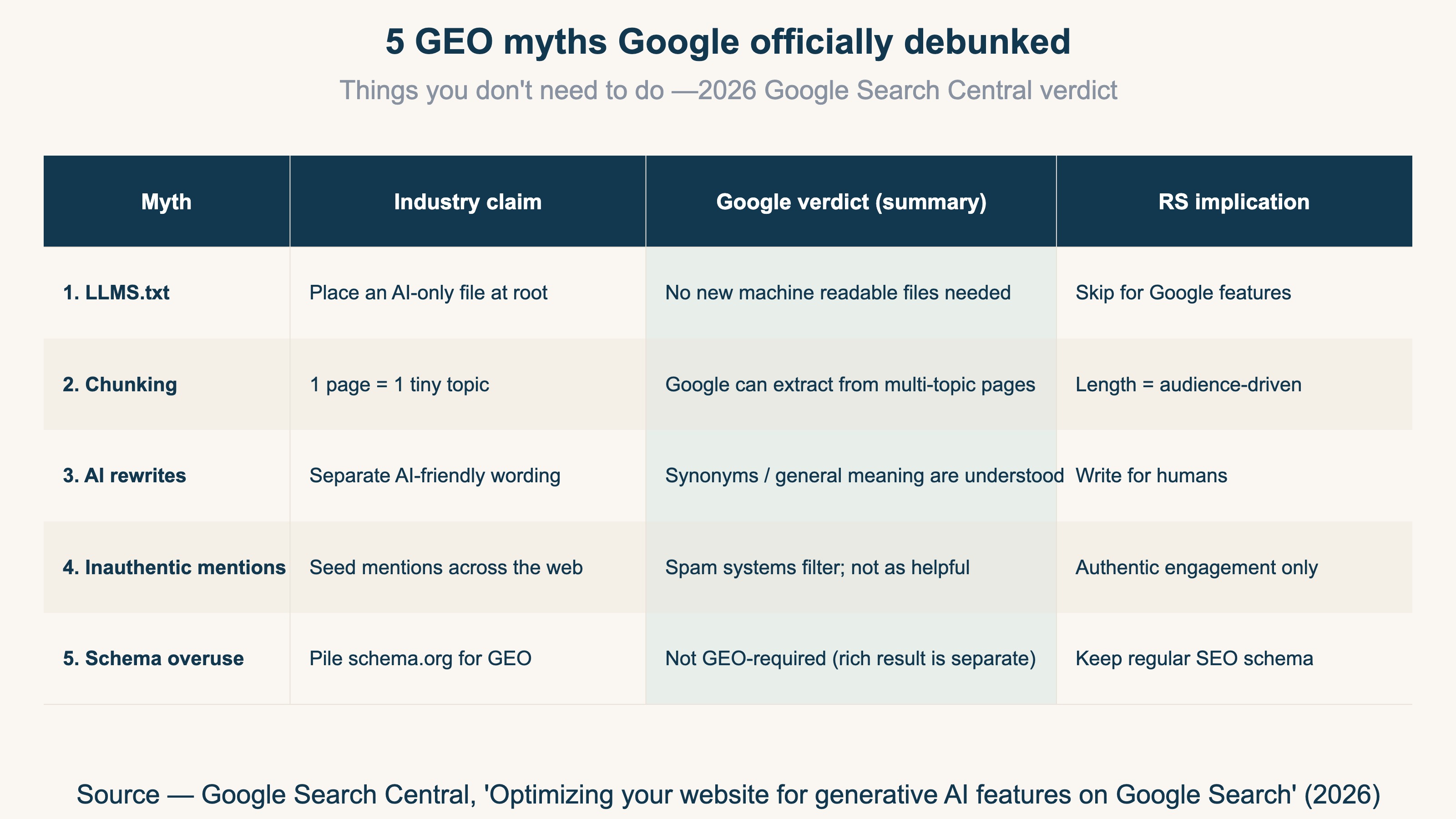
Google Search Central's "Optimizing your website for generative AI features on Google Search" guide (2026) explicitly lists 5 things you do not need to do for generative AI search optimization[1]. Here is each verdict in its full verbatim form, with the background on why the myth spread.
1.1 Myth 1 — LLMS.txt files and other "special" markup#
"LLMS.txt files and other 'special' markup: You don't need to create new machine readable files, AI text files, markup, or Markdown to appear in generative AI search. Note that Google may discover, crawl, and index many kinds of files in addition to HTML on a website: this doesn't mean that the file is treated in a special way."[1]
The industry has been pushing "drop an llms.txt at the root and AI crawlers will prioritize it." For Google features (AI Overview / AI Mode), this is officially confirmed as ineffective. llms.txt for Anthropic / OpenAI / Perplexity is a separate conversation with different crawler semantics — but for Google, you can skip it.
1.2 Myth 2 — "Chunking" content#
"'Chunking' content: There's no requirement to break your content into tiny pieces for AI to better understand it. Google systems are able to understand the nuance of multiple topics on a page and show the relevant piece to users. However, sometimes shorter (or longer!) pages can work well depending on your audience and subject matter."[1]
"LLMs can't handle long content, so split into one-topic-per-page" was a common GEO prescription. Google's position is that a single page covering multiple topics is fine — they extract the relevant section per query. Length should follow the audience and the subject matter, not an arbitrary chunking rule.
1.3 Myth 3 — Rewriting content just for AI systems#
"Rewriting content just for AI systems: You don't need to write in a specific way just for generative AI search. AI systems can understand synonyms and general meanings of what someone is seeking, in order to connect them with content that might not use the same precise words. This means you don't have to worry that you don't have enough 'long-tail' keywords or haven't captured every variation of how someone might seek content like yours."[1]
"You need an AI-friendly voice" or "stuff long-tail variants" — neither is needed. Write for humans; AI handles synonymy and intent matching. This also kills the case for maintaining a separate "AI version" of a page.
1.4 Myth 4 — Seeking inauthentic "mentions"#
"Seeking inauthentic 'mentions': ...seeking inauthentic 'mentions' across the web isn't as helpful as it might seem. Our core ranking systems focus on high-quality content while other systems block spam; our generative AI features depend on both."[1]
"AI features cite brands by name, so you need to seed mentions across blogs and forums" leads to organized mention farms. Google's stance: the spam systems filter this, and high-quality content is what the ranking systems prioritize. Authentic engagement (a genuine community discussion, a technical blog citing your work) is a different axis and remains valuable.
1.5 Myth 5 — Overfocusing on structured data#
"Overfocusing on structured data: Structured data isn't required for generative AI search, and there's no special schema.org markup you need to add. However, it's a good idea to continue using it as part of your overall SEO strategy, as it helps with being eligible for rich results on Google Search."[1]
This one is easily misread. It is not "remove all schema.org." Standard schema (Product / Article / FAQ) for rich result eligibility is still recommended. What Google is calling out is "pile schema specifically for GEO" — there is no GEO-only schema you should be adding.
2. What you should actually do — the GEO mainline#
The GEO mainline is refreshingly simple. Continuing with SEO best practices is the GEO strategy according to Google[1].

The reason is in the mechanics. AI Overview and AI Mode use RAG (Retrieval-augmented generation) and query fan-out (expanding one user query into multiple related queries) on top of the Search index[1][2]. AI features pull from Search results to ground their answers — so "rank high in Search" ≈ "get cited by AI features." There is no separate "GEO ranking system" to game.
Google's "do these things" list breaks down to three axes:
2.1 Write non-commodity content#
Not the "7 Tips for First-Time Homebuyers" pattern that anyone can produce, but first-hand experience or genuinely expert angles — "Why we waived the inspection and saved money," for example[1]. AI features cite content that has unique value worth surfacing.
Practically: lead with data, projects, or experience only your team has. Include at least one differentiated hypothesis or counterargument. Generic how-tos get answered inline by AI anyway, reducing the incentive for users to click through.
2.2 Maintain technical clarity#
Pages need to be indexable + crawlable + snippet eligible, with solid page experience (speed, mobile, clear main content)[1]. This is just "technical SEO" — generative AI features can only cite content that's in the index.
2.3 Avoid variation spam#
Creating a separate page for every keyword variation users might type is a scaled content abuse policy violation[1]. Using AI to mass-produce paraphrased pages to capture long-tail variations gets you penalized by both core ranking and the spam systems.
At RevenueScope we maintain a "no gaps" principle — covering pricing, FAQs, brand axes with structural completeness on a single page. That is different from variation farming. The right direction is "one page that covers all the axes a reader needs," not "the same content reworded across N pages."
3. New axis — agentic experiences worth watching from 2026 onward#
The new piece in Google's guide is agentic experiences — preparing for AI agents that navigate sites autonomously to book, buy, and gather information[1][3]. This is the next GEO frontier.

3.1 Browser agents navigate sites directly#
Google explicitly mentions browser agents that "access your website to gather the data they need to complete these tasks, such as analyzing visual renderings (like screenshots), inspecting the DOM structure, and interpreting the accessibility tree."[1] AI agents interpret sites through three channels: screenshot, DOM, and accessibility tree.
The agent-friendly best practices are documented on web.dev[3] — semantic HTML (<button>, <a>), ARIA attributes, stable layout, click targets ≥8px. This is accessibility work, and it doubles as GEO investment because the same structure that helps screen readers also helps agents.
3.2 Universal Commerce Protocol (UCP) and the MCP ecosystem#
Universal Commerce Protocol (UCP) — emerging protocols for AI agents to compare products and execute orders — runs parallel to the existing MCP (Model Context Protocol) ecosystem[1]. MCP, published by Anthropic in late 2024, is the standard that lets ChatGPT, Cursor, Claude Desktop, Cline, Continue, and other AI agents connect to external data sources in a standardized way.
RevenueScope publishes its own MCP server, exposing analytics data so AI assistants can query industry RPS benchmarks and similar facts directly — rather than guessing from training data.
3.3 RevenueScope's dogfooding angle#
We treat agentic experiences as a first-party axis, not a topic to write about from a distance. Google's note that "if you have extra time, also check the agent-friendly site best practices" is a soft prompt — but building one step ahead of where things are going is exactly what creates the gap 3-6 months out.
After you stop spending cycles on the 5 myths above, the highest-leverage place to redirect that time is agentic experience preparation: semantic HTML hygiene, accessibility work, and watching the MCP / UCP protocol surface area.
Once you debunk each myth and drop the "things you don't need to do," a different question is left standing. Where do you actually stand — are you showing up in AI search, did AI-driven traffic actually grow, and is it driving revenue — and can you measure any of it right now? Dropping the "5 things you don't need" is the first half; the second half is whether you can answer those three questions with numbers. We've published three cluster articles that each go deep on one of them.
RevenueScope solution
"GEO is a myth." "You can't measure AI-driven traffic." People say this, but the three questions about where you stand — are you showing up, did it grow, is it selling — are each measurable. The problem is that neither GA4 nor Search Console breaks AI traffic into these three layers. RevenueScope shows all three.
① Exposure (are you showing up). Which page gets cited, in which AI assistant's answer, and how often. How visible you are in AI search simply doesn't appear in GA4/GSC metrics. How to measure exposure is covered in how visible your brand is in AI search.
② The real gain in AI traffic (did it grow). Even when AI-driven sessions rise, traffic volume alone can't tell you whether that's a genuine gain or just a path shift from visitors you already had. RevenueScope splits it by source and backs the real gain with revenue. The way to tell them apart is in more AI traffic isn't proof it worked.
③ Revenue by source (is it selling). RevenueScope aggregates visits that came from links inside answers by ChatGPT, Claude, Perplexity, Gemini, and Copilot — by landing page and AI source — and shows the revenue too. It's a view GA4 and GSC cannot produce. You can confirm how much AI citations actually drive in revenue, with numbers instead of guesses. AI recommendations skew toward big brands, but smaller players have ways to flip that (why AI recommends big brands).
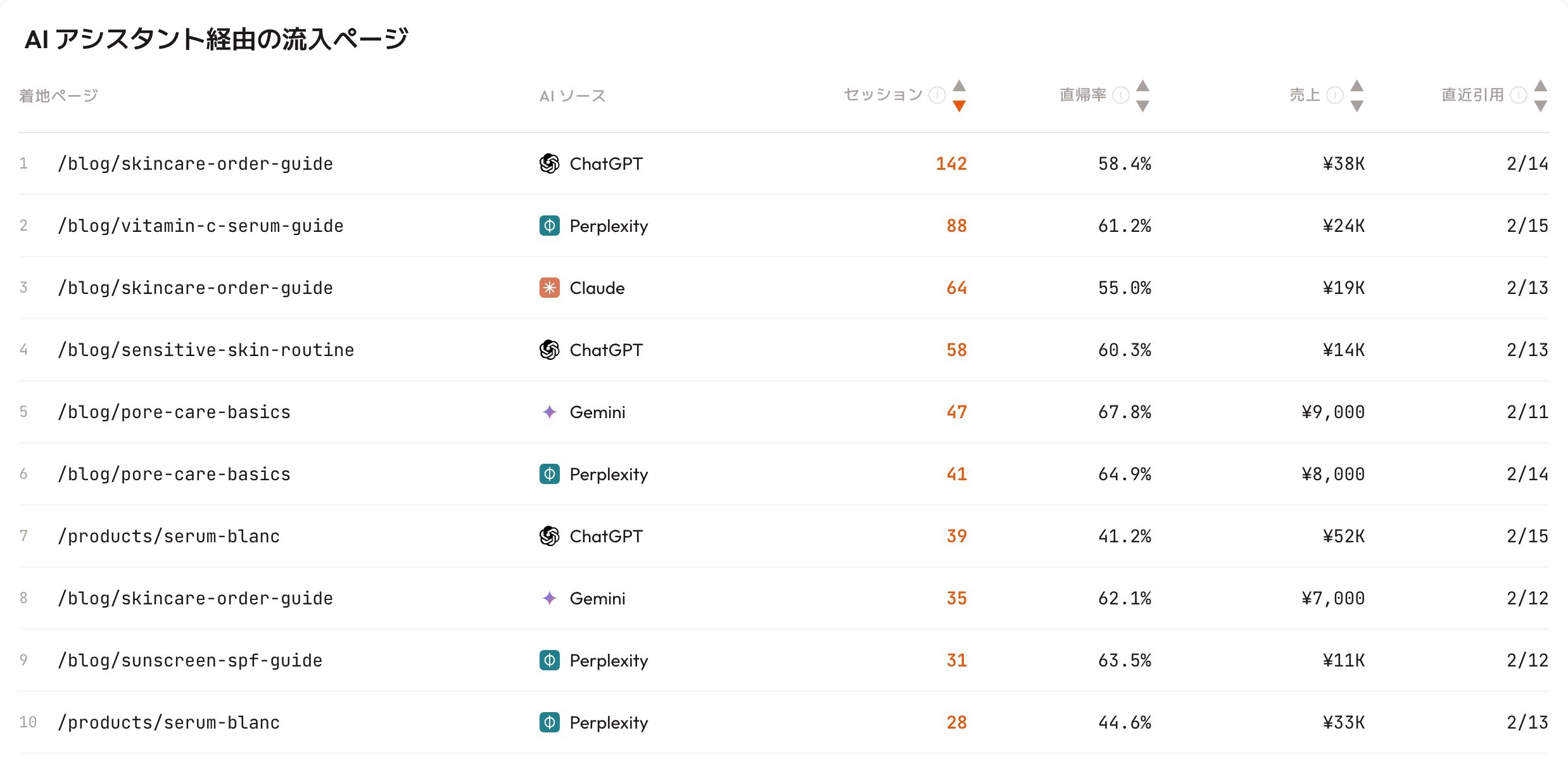
RevenueScope's AI-traffic view (demo data shown). It lines up which page was cited by which AI and how much revenue it produced.
Take the screen above. /blog/skincare-order-guide drew 142 sessions and ¥38K via ChatGPT. Traffic from Perplexity and Claude is listed too, by page and by source. Which article, cited by which AI, drove how much revenue — the area thought to be "unmeasurable" becomes concrete numbers here. Don't let GEO stay a myth; judge AI-citation traffic by revenue. That's the next step toward not leaving traffic on the table in the AI-search era.
4. FAQ#
Q1. I already publish llms.txt. Should I take it down?#
For Google's AI features (AI Overview / AI Mode), it does nothing — so removing it is fine. Other AI vendors (Anthropic, OpenAI, Perplexity) have different crawlers and may use it differently, so the decision comes down to: maintenance cost vs. expected traffic from non-Google AI sources.
Q2. I split my content into one-topic-per-page for chunking. Should I merge them?#
Yes, you can. Google extracts relevant sections from multi-topic pages[1]. Be careful merging pages with weak topical relevance — page experience can suffer. Use "what's readable to a human" as the merge test.
Q3. I piled schema.org for GEO. Should I strip it?#
Keep standard schema (Product, Article, FAQ, etc.) — it's still recommended for rich result eligibility[1]. Remove only the "AI-specific schema" you added speculatively for GEO (custom AI annotations, or markup added purely to emphasize content for AI).
Q4. I rewrote content in an AI-friendly voice and stuffed long-tail keywords. Should I revert?#
Merge any "AI version" pages back to the human version. Long-tail keyword stuffing was never recommended; if you over-indexed on it for GEO specifically, dial it back. Google explicitly says AI understands "synonyms and general meanings"[1].
Q5. If a team had been buying organized brand mentions across blogs and forums, should they continue?#
Stop. Google's spam systems filter inauthentic mentions, and they're distinguished from organic engagement (community discussions, technical blog citations)[1]. Switch budget to authentic engagement — participating in technical discussions related to your product, leaving substantive comments on source articles — which is healthier for GEO and lower-risk on spam.
See which ads actually drive revenue, at a glance
Free up to 5,000 sessions/month, AI analyst included. No credit card required. Up and running in 5 minutes.
References#
- Google Search Central, "Optimizing your website for generative AI features on Google Search", 2026
- Google Search Central Blog, "How Search ranking systems work", 2023 (RAG / query fan-out background)
- web.dev, "Build agent-friendly websites", 2025-2026
![[Research] How Visible Is Your Brand in AI Search? You Can Measure It](/_next/image?url=%2Fimages%2Fnews%2Fai-search-brand-visibility.jpg&w=3840&q=75)
![[Research] More AI Traffic Isn't Proof It Worked: Tell the Real Gain by Revenue](/_next/image?url=%2Fimages%2Fnews%2Fai-referral-revenue-real.jpg&w=3840&q=75)
![[Research] Why AI Recommends Big Brands: A Single Rating Can Flip It](/_next/image?url=%2Fimages%2Fnews%2Fai-recommends-big-brands.jpg&w=3840&q=75)

